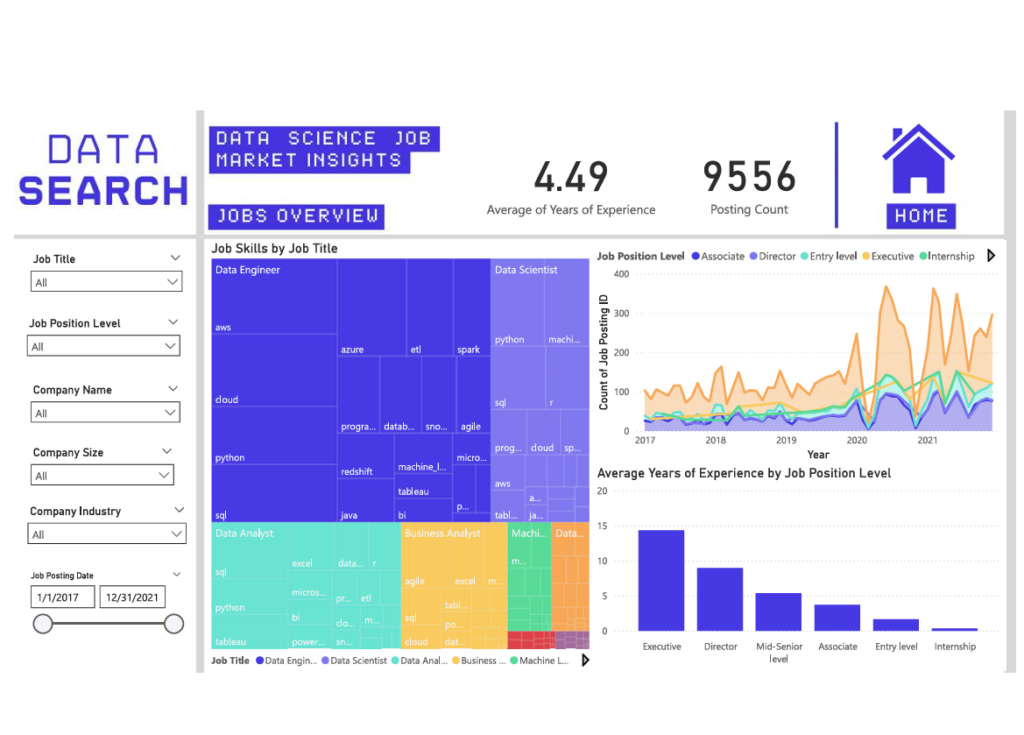
✅ 1. Goals
The primary goals of this case study are:
To analyze the job market landscape across various industries, job roles, and experience levels.
To identify top hiring sectors and understand industry-specific demand.
To determine the skills and qualifications in demand and guide job seekers in aligning their profiles accordingly.
To uncover insights about job postings, salary trends, and regional opportunities.
To support data-driven career decisions for fresh graduates and professionals looking to switch careers or industries.
⚠️ 2. Challenges
Some of the key challenges evident in the case study include:
Data Variety and Volume: The dataset includes multiple job roles, experience ranges, locations, and industries—posing a challenge for meaningful aggregation and analysis.
Missing or Incomplete Data: Certain job posts may have missing salary ranges, location details, or job descriptions, which can lead to skewed insights.
Dynamic Nature of the Job Market: Frequent fluctuations in job trends and hiring priorities make it difficult to draw long-term conclusions.
Identifying Skills Gap: Understanding which skills are most in demand requires precise keyword extraction and clustering from job descriptions.
Location-Based Discrepancies: Demand for roles and salary levels vary significantly across cities or regions, complicating comparisons.
💡 3. Solutions
The case study applies several analytical solutions to address the above challenges:
Power BI Visualizations: The use of slicers, bar charts, pie charts, and trend lines allows dynamic exploration of job data based on industry, role, and location.
Filtering by Experience and Salary: Dashboards allow users to isolate trends by years of experience and salary brackets, helping to target the analysis.
Top 5 Role/Industry Identification: Highlighting the top industries and job roles enables viewers to quickly understand where the highest demand lies.
Regional Analysis: Providing location-based hiring trends to show which cities or regions have the highest job availability.
Data Cleaning and Aggregation: The dataset appears to have been cleaned and transformed to enable accurate comparisons across metrics.